Как Ethereum хранит State
Что такое world state
В блокчейне Ethereum есть world state, который меняется с помощью транзакций. То есть, транзакции агрегируются в блок, появляется новый world state, который залинкован к каждому блоку. При этом блоки и транзакции последовательны. World state есть на всех пирах, каждая нода обменивается блоками и может восстановить у себя этот world state.
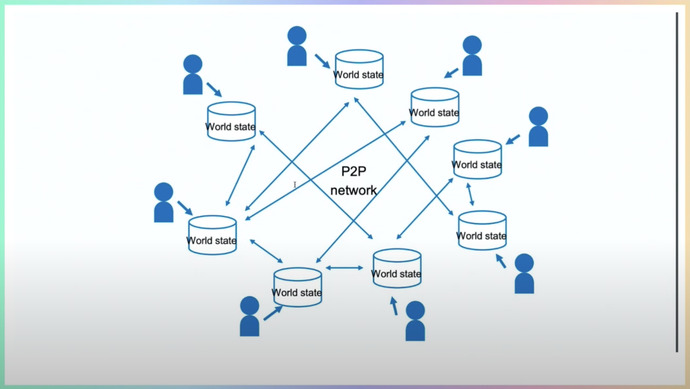
World state в Ethereum
В Ethereum world state выглядит как значение key/value. Где key это адрес, и структура данных, которая хранится как value. Account state состоит из четырех полей:
-
nonce (итератор транзакций);
-
balance (баланс ETH);
-
storage hash (ссылка на сторадж данного адреса);
-
code hash (код EVM контракта, который выполняется при вызове этого адреса).
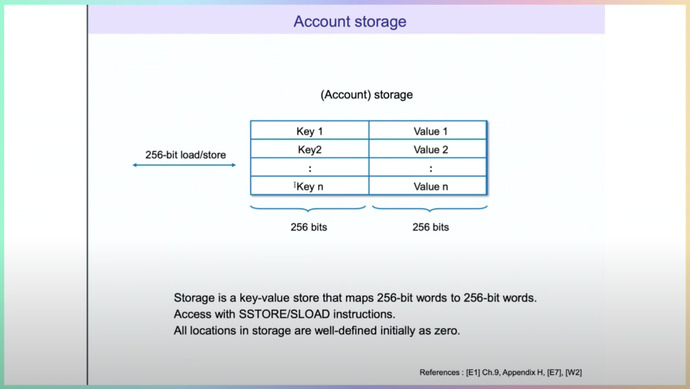
Account storage тоже выглядит как key/value значения, но они по 32 байта. Это произвольные данные, которые может записывать смарт-контракт. Например, при трансфере любого токена под key записывается баланс. В Solidity можно использовать любые системы, и динамические, в том числе. Они по определенным правилам кладутся в key/value в табличку.
Как Биткоин хранит данные?
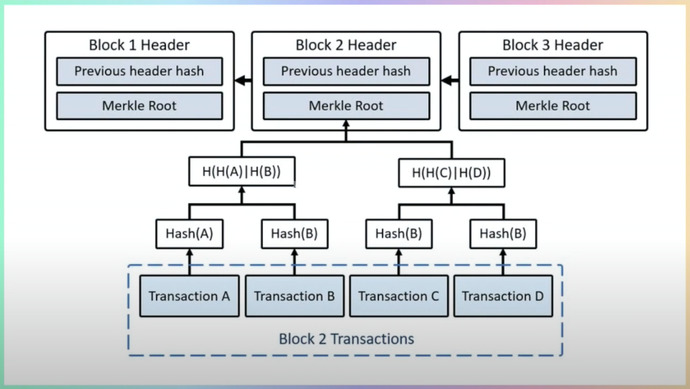
Теоретически можно хранить транзакции списком, но это не оптимально и невозможно быстро проверить, что транзакция была в блоке. Поэтому Биткоин использует деревья Меркла. Хэш каждой транзакции — лист дерева, дальше можно сложить два хэша и получить новый лист. Мы можем доказать при помощи log n, что транзакция a была в блоке 2, например. Нужно предоставить саму транзакцию, а хэш от транзакции b, хэш c+d. Блоки Биткоина идут друг за другом и не содержат ссылку, можно хранить только хэдеры блоков Биткоина и Merkle Root. В таком случае можно доказать, что любая транзакция есть в блоках Биткоина.
Для доказательства, что транзакция действительно хранится в блоке, нужны хедеры блоков до второго ключа, если доказываем, что во втором блоке есть транзакция. В каждом хедере есть Меркл корень. Мы должны полностью получить транзакцию, которую хотим верифицировать. Нужно получить хеш транзакции и хеш транзакции с и c+d. Дальше сравниваем хеши.
Чем хранение данных в Ethereum отличается от Биткоина?
У Ethereum есть три дерева: state, transactions и receipt. Account state показывает, как менялся стейт в данном или прошлом блоке и состояние на данный момент. Transaction Trie — что-то вроде дерева в Биткоине. Receipt root — квитанции для каждой транзакции, которые показывают, какой статус был у транзакции: успешный или неуспешный.
У каждого account state есть key/value, которые лежат в девере Меркла, а также ссылка на сторадж стейт и все это тоже в дереве Меркла. То есть, получается дерево внутри дерева.
В отличие от Биткоина, в Ethereum используется Merkle Patricia Tree. Оно состоит из трех элементов: extension node, branch node, leaf node. Эта структура позволяет найти элементы по некому ключу.
Branch node говорит, что у нас есть 15 значений полубайтов и мы туда можем записать хэш. Идея: берем полубайт нашего ключа, создаем branch ноду и в значение 0 записываем значение следующей branch node и продолжаем так далее. Делим ключ по полубайтам и по ключу можно найти путь, где лежать конкретные данные. Но если мы используем два листа, то нам нужно создавать глубину, равную длине ключа, что не оптимально. Для этого существует extension node, который может сравнить несколько полубайтов общих у ключа и не делать большой глубины. В leaf node, в который можно записать конец ключа.
Также есть префиксы, которые обозначают ли extension node, либо leaf node. Они показывают, что количество полубайтов в key end четное, либо нечетное.
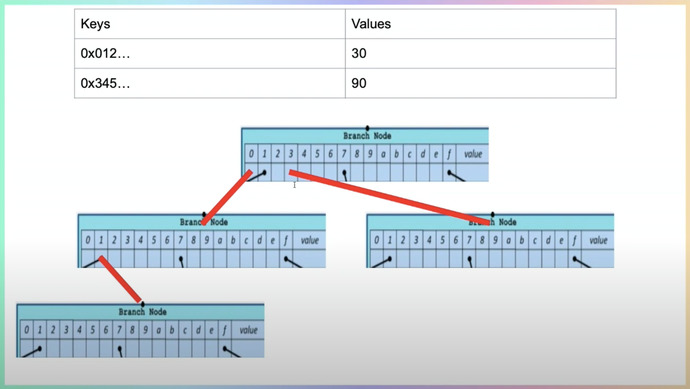
Как хранить информацию в таком дереве: leaf представляет собой account state, а хэш — key от адреса в этом дереве. Value — 32хбайтное значение.
Дерево используется, когда нужно доказать на одном чейне, что происходили некоторые транзакции или залоченные токены. Например, если это бридж между Polygon и Ethereum, нам нужно доказать, что хэш в Polygon соответствует локу в Ethereum.
Алгоритм сериализации в Ethereum
Ethereum есть Recursive-Length Prefix Serialization — простой способ сериализовать данные. В этом представлении есть два вида: bytes и list. Есть некий префикс, который говорит о том, как сериализуются байты. Если байты до 0х80 — то мы можем просто записать как байты, и это будет лежать как значение. Если значение байтов больше 0х80, то мы должны записать сначала длину, а потом значение. Если значение больше 0х55, то мы должны сначала записать, сколько занимает длина в байтах, потом саму длину, и только потом уже значение.
В случае, с list операции происходят примерно те же, с тем отличием, что нужно считать длину всех данных, которые лежат в самом list.

Например, у нас есть список из четырех элементов, как правило, мы берем префикс 0хС4, который является длиной четыре байта и дальше мы записываем по порядку эти байты. Длина листа — префикс минус 0хС.
Когда мы сериализуем слишком большие байты, например 64 байта, то появляется 0хB8, это значит, что мы сначала кодируем длину, а потом пишем саму длину. 40 — 64 байта, и дальше идет само значение (на скрине ниже второй пример).
Потестировать этот сериализатор можно по ссылке toolkit.abdk.consulting/ethereum

Хранение данных после The Merge
После The Merge сеть разделилась на execution layer (Ethereum L1) и consensus layer (Beacon Chain). В Beacon Chain все хранится тоже в дереве. Структура данных больше. Деревья позволяют упростить доказательство данных в блокчейне. Beacon Chain хранит историю всех блок рутов и стейтов. Подробнее про структуры данных в Beacon Chain: https://github.com/ethereum/consensus-specs/blob/dev/specs/phase0/beacon-chain.md.
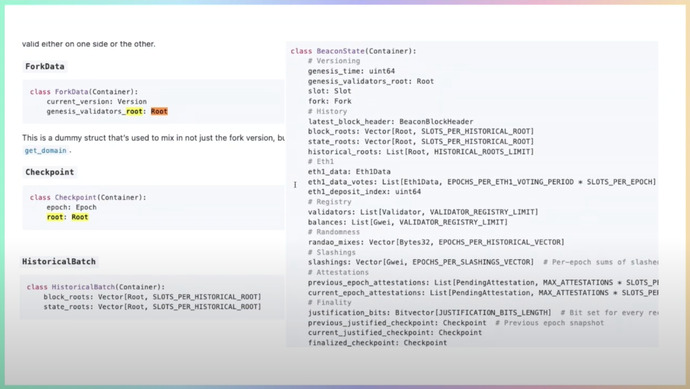
Beacon Chain использует другой способ сериализации данных под названием Simple Serialize (SSZ). Есть некий вектор, вначале нужно записать смещение этого вектора — нужно записать, через сколько от начала данных, начнется информация о векторе. Некая ссылка в array. Дальше нужно записать число и сам вектор. Далее эти сериализованные данные разбиваются по 32 байта и формируют дерево.
