Как выбрать дата провайдера для web3 проекта?
Борис Годлин — computer scientist, один из контрибьюторов Footprint Analytics, который рассказал, как выбрать дата-провайдера для вашего Web 3.0 проекта: L0, L1 или DApp.
Требования
Исторические данные блокчейна хранить в самом блокчейне дорого, поэтому есть потребность в индексирах. Например, кросс-чейн NFT- галерея хочет работать со многими чейнами и в разрезе показывать на разных уровнях (начиная от overview всего рынка и до конкретной коллекции) ее статистику и аналитику, поэтому это самый хороший кейс для примера. У такого Dapp-проекта есть много критериев, которые было бы интересно рассматривать:
- данные должны отвечать вашим целям и задачам;
- данные должны быть хорошего качества;
- количество поддерживаемых сетей должны соответствовать вашим кейсам;
- у вас должны быть простые способы интеграции с индексиром, чтобы легко можно было за фетчить эти данные. Вы, скорее всего, не захотите иметь большие расходы на инфраструктуру, вам будет важна поддержка и, разумеется, legal complince.

Конвейер индексации
Существует много блокчейнов, а значит, много сырых данных. После того как сырые данные получены, для большинства юзкейсов понадобится абстракция. Процесс индексации предусматривает тривиальные процессы: вы откуда-то берете данные, преобразуете их, сохраняете. Существует множество способов хранения данных, разные виды баз данных. Но после того как вы сохранили их, вы хотите иметь возможность предоставлять разные интерфейсы с работой этих данных. Команда Footprint Analytics делает две сегментации: для аналитиков и для разработчиков.
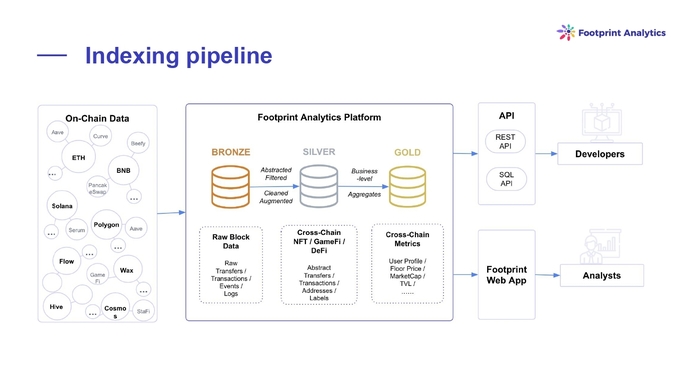
Типы RPC нод
Есть множество разных видов нод, которые хранят разные массивы данных . Если вы хотите получить исторические данные из блокчейна, вам придется работать с архивными нодами.

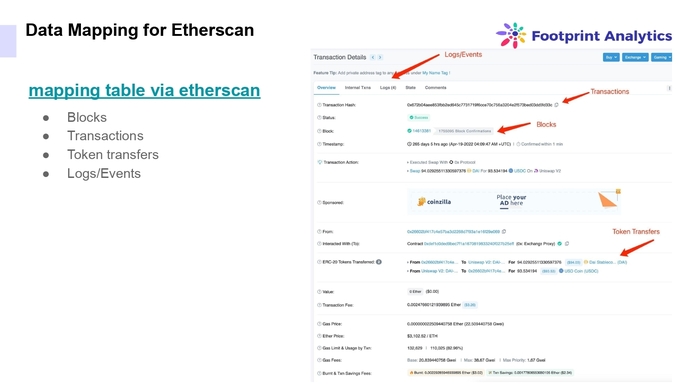
Отображение данных для Etherscan
Делая референс на EVM (т.к. он популярный и многие знают, как он устроен) есть 4 примитивы. Это блоки, транзакции, логи и трейсы — сырые данные, которые можно получить с блокчейна. Чем и занимаются специалисты Footprint Analytics. Если вы когда-то работали с Etherscan или писали смарт-контракты, вы должны знать, как это работает.
Почему необработанных данных недостаточно
Сырых данных может быть недостаточно. В том случае, если вы NFT-галерея, которая хочет работать с несколькими сетями помимо EVM: с Polkadot или Solana, нужно понимать, что это архитектурно совершенно разные сети. Так как имеются разные сырые данные, а вы бы хотели в рамках одного запроса иметь возможность получить их по разным сетям одновременно, то нужно абстрагироваться от этих сырых данных. Поэтому абстракции имеют место.

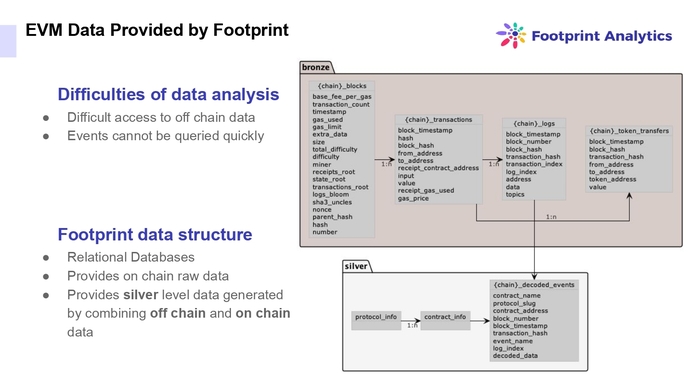
Данные EVM, предоставленные Footprint
В Footprint Analytics агрегируют сырые данные и если они соответствуют каким-то правилам (например, транзакция выполнена в рамках смарт-контракта, который из себя представляет стандарты ERC-721 или ERC-1155, то есть имплементируют методы), то считается, что это NFT-транзакция. У Footprint Analytics много правил, которые разнятся от EVM до Solana. Они агрегируют это в рамках “bronze stable” до уровня “silver stable”, где уже находится все по всем сетям.
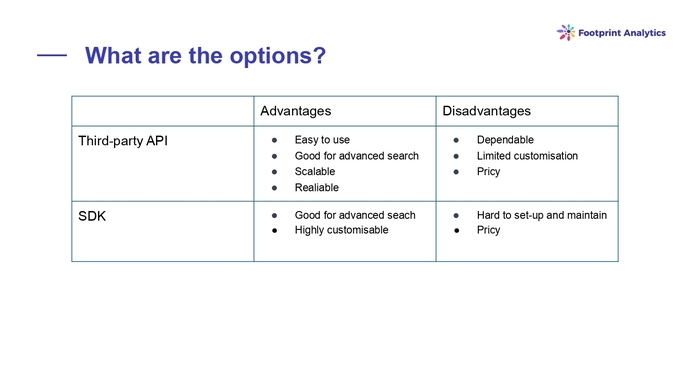
Какие есть опции
Опции две: либо вы кому-то доверяете и получается данные, либо вы сам индексер.
Сторонние продукты гораздо проще использовать, ведь за вас уже построили инфраструктуру. Компания, которая разрабатывает такой API, зачастую имеет высокие вычислительные мощности, в ней работают профессионалы. Тем не менее, вы зависимы от индексера, вы имеете меньше возможности кастомизации и это может быть недешево.
В случае SDK — все в ваших руках и вы сами выстраиваете всю абстракцию и триггеры. Это легко кастомизируется, но тяжело устанавливается и поддерживается, что подразумевает большее количество ресурсов.
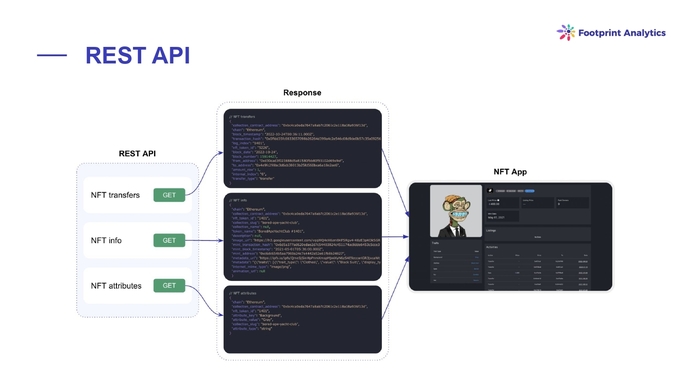
REST API
Footprint Analytics имеет два интерфейса под разные сегменты: под разработчиков и аналитиков. В конечном итоге data set — единственный. Это означает, что все что вы можете получить через веб-приложение, можно потом получить через API.
У Footprint Analytics есть несколько способов API интеграций. Один из них — REST. Это когда выбраны какие-то тривиальные comand-сценарии, по которым вы можете получить данные.
SQL API
В основании всего у Footprint Analytics реляционная база данных, потому что количество инструментов и кейсов, которые работают с реляционными базами данных, универсально. И нужно понимать, что наши данные используют SQL.Это очень интересная вещь по той причине, что любой запрос, который вы исполняете через браузер и получаете красивый чарт или таблицу, вы можете валидировать. Можете убедиться в том, что вы получаете то, что вы хотите получить, и что данные приходят верные. Потом просто скопировать SQL-код, который получаете, и вставить ее в API, и использовать в рамках API. Footprint Analytics продвигает экосистемный подход соединения веб-приложения и API.
Миссия Footprint Analytics опустить барьер входа для блокчейн аналитики, команда проекта делает абстракцию над SQL в виде construct building и потому с API у них такой же подход.

Поддерживаемые сети
Footprint Analytics поддерживает 24 сети, более 700 тысяч NFT-коллекций, 17 NFT-маркетплейсов и 519 DeFi протколов.

